System Development with Python
Week 5 :: XML
Today's topics
- Python XML libs
XML
Extensible Markup Language (XML) defines a set of rules for encoding documents in a format that is both human- and machine-readable.
It's been around since about 1996, so all major platforms have good support
Has robust validation frameworks: Document Type Definition (DTD) and XML Schema Definition (XSD)
Subject to vulnerabilities. (For example examples/billion_lolz.py)
Wikipedia example
In the repository you'll find a random portion of the wikipedia database, found in examples/data/enwiki-latest-pages-articles1.xml-p000000010p000010000-shortened.bz2
Original source is here http://dumps.wikimedia.org/enwiki/latest/enwiki-latest-pages-articles1.xml-p000000010p000010000.bz2, but it's pretty big so we'll just use a subset of it.
We'll parse this using several of the tools presented.
SAX versus DOM
SAX - Simple API for XML
- Event based stream processing
- Document is processed element by element, so it is efficient for large documents
- You have to keep track of location in the tree, bookkeeping gets tricky
- Not efficient for random access
- Can't insert or delete nodes
DOM - Document Object Model
- Easy to find elements with DOM methods, XPath, etc.
- More efficient for random access
- Docment is usually stored in memory, so not suitable for large documents
- Can insert and delete nodes
xml.sax
The xml.sax package provides a number of modules which implement the Simple API for XML (SAX) interface for Python
A SAX application has three kinds of objects: readers, handlers, and input sources
- Input sources provide the raw stream of XML bytes from a source such as a file or the network
- Readers, also known as parsers, parse the stream into elements and generate events
- Handlers handle the events generated by the reader to do useful work
Handling SAX events
xml.sax.handler defines 4 kinds of handlers:
- content handlers
- DTD handlers
- error handlers
- entity resolvers
The most important handler for getting your job done is xml.sax.handler.ContentHandler
To create your handler, just subclass ContentHandler
3 methods are necessary to override in order to get element data:
- ContentHandler.startElement(name, attrs)
- ContentHandler.endElement(name)
- ContentHandler.characters(content) - returns a chunk of character data, which may be all contiguous character data in one chunk (string), or split into more than one chunk
wikipedia-sax.py
examples/wikipedia-sax.py creates a handler which logs the content of every <title> tag it encounters
Try running this to make sure it works
Now it's your turn.
- The data consists of <page> elements for each page.
- The current revision's author is stored as page/revision/contributor/username.
- Modify wikipedia-sax.py to log every username tag
- How can we list the username with the most contributions in this data after the document is done parsing?
xml.dom
The xml.dom package provides a number of modules which implement the Document Object Model API
A reference implementation is in xml.dom.minidom - Minimal DOM implementation
DOM is an RFC standard which minidom implements. If you've done DOM manipulation in Javascript, the methods will be familiar: createElement, getElementsByTagName, appendChild, ..
xml.dom.minidom
To get a reference to a Document object for your XML, just pass it to one of the parse methods:
- xml.dom.minidom.parse(filename_or_file[, parser[, bufsize]])
- xml.dom.minidom.parseString(string[, parser])
The optional parser argument is for passing a SAX2 parser object
You can also create a Document from scratch by calling a method on a "DOM Implementation" object:
from xml.dom.minidom import getDOMImplementation
impl = getDOMImplementation()
newdoc = impl.createDocument(None, "some_tag", None)
top_element = newdoc.documentElement
text = newdoc.createTextNode('Some textual content.')
top_element.appendChild(text)
manipulating the DOM
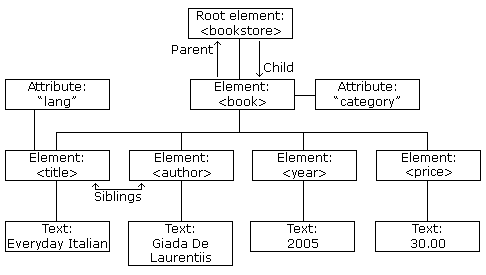
Duplicate a node with node.cloneNode(deep) # True or False to specify a deep or shallow copy
Get a reference to a node's parent with node.parentNode
append a node to another with node.appendChild(element)
Create a new node with document.createElement('elementname')
wikipedia-minidom.py
examples/wikipedia-minidom.py reads a Document, then logs the content of every <title> tag it encounters
Try running this to make sure it works
Now it's your turn.
- The data consists of <page> elements for each page.
- Modify wikipedia-minidom.py to create a new last page which is a copy of the existing last page
- Add a new element, <modifiedby> containing your superhero name to your new page element
- Useful properties and methods may include those on the previous page: parentNode, cloneNode, appendChild, createElement
- You can output a human readable version with the method document.toprettyxml. The encoding kwarg may be helpful.
xml.etree.ElementTree — The ElementTree XML API
Integrated into Python 2.5, provides a more Pythonic API to the document, not tied to the DOM standard
Provides limited XPath support
xml.etree.cElementTree is a compatible C implementation
Creating an ElementTree
Parse a file with xml.etree.ElementTree.parse
Parse an XML string with xml.etree.ElementTree.fromstring
Write out an ElementTree with xml.etree.ElementTree.write(f) # filename or file object
XML Namespaces
A W3C specification for uniquely identifying elements and attributes in an XML document
Multiple namespaces can be included in one document
Namespace names are URIs, strings chosen for their uniqueness property. Nothing is implied about the data behind the URI.
XML namespace definitions are added to an element, and apply to all child elements. Thus they are usually applied to the root element. For instance, in our sample data the root element is:
<mediawiki xmlns="http://www.mediawiki.org/xml/export-0.8/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.mediawiki.org/xml/export-0.8/ http://www.mediawiki.org/xml/export-0.8.xsd" version="0.8" xml:lang="en" >
The namespace of an element is indicated by adding prefix: to the element, e.g.
<html:p>explicit html p tag</html:p >
Namespaces in ElementTree
In an Element tree, qualified names are stored fully qualified in "Clark's notation", which is a single string of the form {uri}local, e.g. {http://www.mediawiki.org/xml/export-0.8/}page
When locating elements in a namespaced document, either pass the fully qualified name in the form above to find/findall/iterfind, or add the namespaces kwarg. e.g.
namespaces = {'xmlns': 'http://www.mediawiki.org/xml/export-0.8/'}
for title in root.findall('xmlns:page/xmlns:title', namespaces=namespaces):
wikipedia-elementtree.py
examples/wikipedia-elementtree.py logs the content of every <title> tag it encounters
Try running this to make sure it works
Now it's your turn, do the same author counting as with SAX, but this time use ElementTree.
- The data consists of <page> elements for each page.
- The current revision's author is stored as page/revision/contributor/username.
- Modify wikipedia-elementtree.py to determine the username of the author with the most contributions in this data
lxml
lxml is Python binding for the C libraries libxml2 and libxslt
Does not ship with Python
provides an interface similar to ElementTree
provides a SAX compliant API
has a focus on performance
Questions?
/