Session 04¶

Paul Downey http://www.flickr.com/photos/psd/492139935/ - CC-BY
Scraping, APIs and Mashups¶
Wherein we learn how to make order from the chaos of the wild internet.
A Dilemma¶
The internet makes a vast quantity of data available.
But not always in the form or combination you want.
It would be nice to be able to combine data from different sources to create meaning.
The Big Question¶
But How?
The Big Answer¶
Mashups
Mashups¶
A mashup is:
a web page, or web application, that uses and combines data, presentation
or functionality from two or more sources to create new services.
-- wikipedia (http://en.wikipedia.org/wiki/Mashup_(web_application_hybrid))
Data Sources¶
The key to mashups is the idea of data sources.
These come in many flavors:
- Simple websites with data in HTML
- Web services providing structured data
- Web services providing tranformative service (geocoding)
- Web services providing presentation (mapping)
Web Scraping¶
It would be nice if all online data were available in well-structured formats.
The reality is that much data is available only in HTML.
Still we can get at it, with some effort.
By scraping the data from the web pages.
HTML¶
Ideally, it looks like this:
<!DOCTYPE html>
<html>
<head>
</head>
<body>
<p>A nice clean paragraph</p>
<p>And another nice clean paragraph</p>
</body>
</html>
But in real life, it’s more often like this:
<html>
<form>
<table>
<td><input name="input1">Row 1 cell 1
<tr><td>Row 2 cell 1
</form>
<td>Row 2 cell 2<br>This</br> sure is a long cell
</body>
</html>

Photo by Matthew via Flickr (http://www.flickr.com/photos/purplemattfish/3918004964/) - CC-BY-NC-ND
“Be strict in what you send and tolerant in what you receive”
Taming the Mess¶
Luckily, there are tools to help with this.
In python there are several candidates, but I like BeautifulSoup.
BeautifulSoup is a great tool, but it’s not in the Standard Library.
We’ll need to install it.
Create a virtualenv to do so:
$ pyvenv soupenv
...
$ source soupenv/bin/activate
(remember, for Windows users that should be soupenv/Scripts/activate.bat)
Once the virtualenv is activated, you can simply use pip or easy_install to install the libraries you want:
(soupenv)$ pip install beautifulsoup4
BeautifulSoup is built to use the Python HTMLParser.
- Batteries Included. It’s already there
- It’s not great, especially before Python 2.7.3
BeautifulSoup also supports using other parsers.
There are two good choices: lxml and html5lib.
lxml is better, but much harder to install. Let’s use html5lib.
Again, this is pretty simple:
(soupenv)$ pip install html5lib
Once installed, BeautifulSoup will choose it automatically.
BeautifulSoup will choose the “best” available.
You can specify the parser if you need to for some reason.
In fact, in recent versions of BeautifulSoup, you’ll be warned if you don’t (though you can ignore the warning).
Python provides tools for opening urls and communicating with servers. It’s
spread across the urllib and urllib2 packages.
These packages have pretty unintuitive APIs.
The requests library is becoming the de-facto standard for this type of
work. Let’s install it too.
(soupenv)$ pip install requests
Our Class Mashup¶
We’re going to explore some tools for making a mashup today
We’ll be starting by scraping restaurant health code data for a given ZIP code
Then, we’ll look up the geographic location of those zipcodes using Google
Finally, we’ll display the results of our work on a map
Start by opening a new file in your editor: mashup.py.
The source for the data we’ll be displaying is a search tool provided by King County.
It’s supposed to have a web service, but the service is broken.
Luckily, the HTML search works just fine.
Open the search form in your browser.
Fill in a ZIP code (perhaps 98101).
Add a start and end date (perhaps about 1 or 2 years apart).
Submit the form, and take a look at what you get.
Next we want to automate the process.
Copy the domain and path of the url into your new mashup.py file like
so:
INSPECTION_DOMAIN = "http://info.kingcounty.gov"
INSPECTION_PATH = "/health/ehs/foodsafety/inspections/Results.aspx"
Next, copy the query parameters from the URL and convert them to a dictionary:
INSPECTION_PARAMS = {
'Output': 'W',
'Business_Name': '',
'Business_Address': '',
'Longitude': '',
'Latitude': '',
'City': '',
'Zip_Code': '',
'Inspection_Type': 'All',
'Inspection_Start': '',
'Inspection_End': '',
'Inspection_Closed_Business': 'A',
'Violation_Points': '',
'Violation_Red_Points': '',
'Violation_Descr': '',
'Fuzzy_Search': 'N',
'Sort': 'H'
}
Fetching Search Results¶
Next we’ll use the requests library to write a function to fetch these
results on demand.
In requests, each HTTP method has a module-level function:
GET==requests.get(url, **kwargs)POST==requests.post(url, **kwargs)- ...
kwargs represent other parts of an HTTP request:
params: a dict of url parameters (?foo=bar&baz=bim)headers: a dict of headers to send with the requestdata: the body of the request, if any (form data for POST goes here)- ...
The return value from one of these functions is a response object which
provides:
response.status_code: see the HTTP Status Code returnedresponse.ok: True ifresponse.status_codeis not an errorresponse.raise_for_status(): call to raise a python error if it isresponse.headers: The headers sent from the serverresponse.text: Body of the response, decoded to unicoderesponse.encoding: The encoding used to decoderesponse.content: The original encoded response body as bytes
requests documentation: http://docs.python-requests.org/en/latest/
We’ll start by writing a function get_inspection_page
- It will accept keyword arguments for each of the possible query values
- It will build a dictionary of request query parameters from incoming keywords, using INSPECTION_PARAMS as a template
- It will make a request to the inspection service search page using this query
- It will return the encoded content and the encoding used as a tuple
Try writing this function. Put it in mashup.py
My Solution¶
Here’s the one I created:
import requests
def get_inspection_page(**kwargs):
url = INSPECTION_DOMAIN + INSPECTION_PATH
params = INSPECTION_PARAMS.copy()
for key, val in kwargs.items():
if key in INSPECTION_PARAMS:
params[key] = val
resp = requests.get(url, params=params)
resp.raise_for_status()
return resp.text
Parse the Results¶
Next, we’ll need to parse the results we get when we call that function
But before we start, a word about parsing HTML with BeautifulSoup
The BeautifulSoup object can be instantiated with a string or a file-like object as the sole argument:
from bs4 import BeautifulSoup
parsed = BeautifulSoup('<h1>Some HTML</h1>')
fh = open('a_page.html', 'r')
parsed = BeautifulSoup(fh)
page = urllib2.urlopen('http://site.com/page.html')
parsed = BeautifulSoup(page)
You might want to open the documentation as reference (http://www.crummy.com/software/BeautifulSoup/bs4/doc)
My Solution¶
Take a shot at writing this new function in mashup.py
# add this import at the top
from bs4 import BeautifulSoup
# then add this function lower down
def parse_source(html):
parsed = BeautifulSoup(html)
return parsed
Put It Together¶
We’ll need to make our script do something when run.
if __name__ == '__main__':
# do something
- Fetch a search results page
- Parse the resulting HTML
- For now, print out the results so we can see what we get
Use the prettify method on a BeautifulSoup object:
print(parsed.prettify())
My Solution¶
Try to come up with the proper code on your own. Add it to mashup.py
if __name__ == '__main__':
use_params = {
'Inspection_Start': '2/1/2013',
'Inspection_End': '2/1/2015',
'Zip_Code': '98101'
}
html = get_inspection_page(**use_params)
parsed = parse_source(html)
print(parsed.prettify())
Assuming your virtualenv is still active, you should be able to execute the script.
(soupenv)$ python mashup.py
...
<script src="http://www.kingcounty.gov/kcscripts/kcPageAnalytics.js" type="text/javascript">
</script>
<script type="text/javascript">
//<![CDATA[
var usasearch_config = { siteHandle:"kingcounty" };
var script = document.createElement("script");
script.type = "text/javascript";
script.src = "http://search.usa.gov/javascripts/remote.loader.js";
document.getElementsByTagName("head")[0].appendChild(script);
//]]>
</script>
</form>
</body>
</html>
This script is available as resources/session04/mashup_1.py
Now, let’s re-run the script, saving the output to a file so we can use it later:
$ python mashup.py > inspection_page.html
Then add a quick function to our script that will use these saved results:
def load_inspection_page(name):
file_path = pathlib.Path(name)
return file_path.read_text(encoding='utf8')
Finally, bolt that in to your script to use it:
# COMMENT OUT THIS LINE AND REPLACE IT
# html = get_inspection_page(**use_params)
html = load_inspection_page('inspection_page.html')
Extracting Data¶
Next we find the bits of this pile of HTML that matter to us.
Open the page you just wrote to disk in your web browser and open the developer tools to inspect the page source.
You’ll want to start by finding the element in the page that contains all our search results.
Look at the source and identify the single element we are looking for.
Having found it visually, we can now search for it automatically. In BeautifulSoup:
- All HTML elements (including the parsed document itself) are
tags - A
tagcan be searched using itsfindorfind_allmethods - This searches the descendents of the tag on which it is called.
- It takes arguments which act as filters on the search results
like so:
tag.find(name, attrs, recursive, text, **kwargs)
tag.find_all(name, attrs, recursive, text, limit, **kwargs)
The find method allows us to pass kwargs.
Keywords that are not among the named parameters will be considered an HTML attribute.
We can use this to find the column that holds our search results:
content_col = parsed.find('td', id="contentcol")
Add that line to our mashup script and try it out:
#...
parsed = parse_source(html)
content_col = parsed.find("td", id="contentcol")
print content_col.prettify()
(soupenv)$ python mashup.py
<td id="contentcol">
...
</td>
The next job is to find the inspection data we can see when we click on the restaurant names in our page.
Do you notice a pattern in how that data is structured?
For each restaurant in our results, there are two <div> tags.
The first contains the content you see at first, the second the content that displays when we click.
What can you see that identifies these items?
<div id="PR0084952"...> and <div id="PR0084952~"...>
Each pair shares an ID, and the stuff we want is in the second one
Each number is different for each restaurant
We can use a regular expression to help us here.
Let’s write a function in mashup.py that will find all the divs in our
column with the right kind of id:
- It should match
<div>tags only - It should match ids that start with
PR - It should match ids that contain some number of digits after that
- It should match ids that end with a tilde (
~) character
# add an import up top
import re
# and add this function
def restaurant_data_generator(html):
id_finder = re.compile(r'PR[\d]+~')
return html.find_all('div', id=id_finder)
Let’s add that step to the main block at the bottom of mashup.py (only
print the first of the many divs that match):
html, encoding = load_inspection_page('inspection_page.html')
parsed = parse_source(html, encoding)
content_col = parsed.find("td", id="contentcol")
data_list = restaurant_data_generator(content_col)
print data_list[0].prettify()
Finally, test it out:
(soupenv)$ python mashup.py
<div id="PR0001203~" name="PR0001203~" onclick="toggleShow(this.id);"...>
<table style="width: 635px;">
...
</table>
</div>
This code is available as /resources/session04/mashup_2.py
Parsing Restaurant Data¶
Now that we have the records we want, we need to parse them.
We’ll start by extracting information about the restaurants:
- Name
- Address
- Location
How is this information contained in our records?
Each record consists of a table with a series of rows (<tr>).
The rows we want at this time all have two cells inside them.
The first contains the label of the data, the second contains the value
We’ll need a function in mashup.py that:
- takes an HTML element as an argument
- verifies that it is a
<tr>element - verifies that it has two immediate children that are
<td>elements
My solution:
def has_two_tds(elem):
is_tr = elem.name == 'tr'
td_children = elem.find_all('td', recursive=False)
has_two = len(td_children) == 2
return is_tr and has_two
Let’s try this out in an interpreter:
In [1]: from mashup_3 import load_inspection_page, parse_source,
restaurant_data_generator, has_two_tds
In [2]: html = load_inspection_page('inspection_page.html')
In [3]: parsed = parse_source(html)
...
In [4]: content_col = parsed.find('td', id='contentcol')
In [5]: records = restaurant_data_generator(content_col)
In [6]: rec = records[4]
We’d like to find all table rows in that div that contain two cells
The table rows are all contained in a <tbody> tag.
We only want the ones at the top of that tag (ones nested more deeply contain other data)
In [13]: data_rows = rec.find('tbody').find_all(has_two_tds, recursive=False)
In [14]: len(data_rows)
Out[14]: 7
In [15]: print(data_rows[0].prettify())
<tr>
<td class="promptTextBox" style="width: 125px; font-weight: bold">
- Business Name
</td>
<td class="promptTextBox" style="width: 520px; font-weight: bold">
SPICE ORIENT
</td>
</tr>
Now we have a list of the rows that contain our data.
Next we have to collect the data they contain
The label/value structure of this data should suggest the right container to store the information.
Let’s start by trying to get at the first label
In [18]: row1 = data_rows[0]
In [19]: cells = row1.find_all('td')
In [20]: cell1 = cells[0]
In [21]: cell1.text
Out[21]: '\n - Business Name\n '
That works well enough, but all that extra stuff is nasty
We need a method to clean up the text we get from these cells
It should strip extra whitespace, and characters like - and : we
don’t want.
Try writing such a function for yourself now in mashup.py
def clean_data(td):
return td.text.strip(" \n:-")
Add it to your interpreter and test it out:
In [25]: def clean_data(td):
....: return td.text.strip(" \n:-")
....:
In [26]: clean_data(cell1)
Out[26]: 'Business Name'
In [27]:
Ahhh, much better
So we can get a list of the rows that contain label/value pairs.
And we can extract clean values from the cells in these rows
Now we need a function in mashup.py that will iterate through the rows
we find and build a dictionary of the pairs.
We have to be cautious because some rows don’t have a label.
The values in these rows should go with the label from the previous row.
Here’s the version I came up with:
def extract_restaurant_metadata(elem):
restaurant_data_rows = elem.find('tbody').find_all(
has_two_tds, recursive=False
)
rdata = {}
current_label = ''
for data_row in restaurant_data_rows:
key_cell, val_cell = data_row.find_all('td', recursive=False)
new_label = clean_data(key_cell)
current_label = new_label if new_label else current_label
rdata.setdefault(current_label, []).append(clean_data(val_cell))
return rdata
Add it to our script:
# ...
data_list = restaurant_data_generator(content_col)
for data_div in data_list:
metadata = extract_restaurant_metadata(data_div)
print metadata
And then try it out:
(soupenv)$ python mashup.py
...
{u'Business Category': [u'Seating 0-12 - Risk Category III'],
u'Longitude': [u'122.3401786000'], u'Phone': [u'(206) 501-9554'],
u'Business Name': [u"ZACCAGNI'S"], u'Address': [u'97B PIKE ST', u'SEATTLE, WA 98101'],
u'Latitude': [u'47.6086651300']}
This script is available as resources/session04/mashup_3.py
Extracting Inspection Data¶
The final step is to extract the inspection data for each restaurant.
We want to capture only the score from each inspection, details we can leave behind.
We’d like to calculate the average score for all known inspections.
We’d also like to know how many inspections there were in total.
Finally, we’d like to preserve the highest score of all inspections for a restaurant.
We’ll add this information to our metadata about the restaurant.
Let’s start by getting our bearings. Return to viewing the
inspection_page.html you saved in a browser.
Find a restaurant that has had an inspection or two.
What can you say about the HTML that contains the scores for these inspections?
I notice four characteristics that let us isolate the information we want:
- Inspection data is containd in
<tr>elements - Rows with inspection data in them have four
<td>children - The text in the first cell contains the word “inspection”
- But the text does not start with the word “inspection”
Let’s try to write a filter function like the one above that will catch these rows for us.
Add this new function is_inspection_data_row to mashup.py
def is_inspection_data_row(elem):
is_tr = elem.name == 'tr'
if not is_tr:
return False
td_children = elem.find_all('td', recursive=False)
has_four = len(td_children) == 4
this_text = clean_data(td_children[0]).lower()
contains_word = 'inspection' in this_text
does_not_start = not this_text.startswith('inspection')
return is_tr and has_four and contains_word and does_not_start
We can test this function by adding it into our script:
for data_div in data_list:
metadata = extract_restaurant_metadata(data_div)
# UPDATE THIS BELOW HERE
inspection_rows = data_div.find_all(is_inspection_data_row)
print(metadata)
print(len(inspection_rows))
print('*'*10)
And try running the script in your terminal:
(soupenv)$ python mashup.py
{u'Business Category': [u'Seating 0-12 - Risk Category III'],
u'Longitude': [u'122.3401786000'], u'Phone': [u'(206) 501-9554'],
u'Business Name': [u"ZACCAGNI'S"], u'Address': [u'97B PIKE ST', u'SEATTLE, WA 98101'],
u'Latitude': [u'47.6086651300']}
0
**********
Now we can isolate a list of the rows that contain inspection data.
Next we need to calculate the average score, total number and highest score for each restaurant.
Let’s add a function to mashup.py that will:
- Take a div containing a restaurant record
- Extract the rows containing inspection data
- Keep track of the highest score recorded
- Sum the total of all inspections
- Count the number of inspections made
- Calculate the average score for inspections
- Return the three calculated values in a dictionary
Try writing this routine yourself.
def get_score_data(elem):
inspection_rows = elem.find_all(is_inspection_data_row)
samples = len(inspection_rows)
total = high_score = average = 0
for row in inspection_rows:
strval = clean_data(row.find_all('td')[2])
try:
intval = int(strval)
except (ValueError, TypeError):
samples -= 1
else:
total += intval
high_score = intval if intval > high_score else high_score
if samples:
average = total/float(samples)
return {'Average Score': average, 'High Score': high_score,
'Total Inspections': samples}
We can now incorporate this new routine into our mashup script.
We’ll want to add the data it produces to the metadata we’ve already extracted.
for data_div in data_list:
metadata = extract_restaurant_metadata(data_div)
inspection_data = get_score_data(data_div)
metadata.update(inspection_data)
print metadata
And test it out at the command line:
(soupenv)$ python mashup.py
...
{u'Business Category': [u'Seating 0-12 - Risk Category III'],
u'Longitude': [u'122.3401786000'], u'High Score': 0,
u'Phone': [u'(206) 501-9554'], u'Business Name': [u"ZACCAGNI'S"],
u'Total Inspections': 0, u'Address': [u'97B PIKE ST', u'SEATTLE, WA 98101'],
u'Latitude': [u'47.6086651300'], u'Average Score': 0}
Break Time¶
Once you have this working, take a break.
When we return, we’ll try a saner approach to getting data from online
Another Approach¶
Scraping web pages is tedious and inherently brittle
The owner of the website updates their layout, your code breaks
But there is another way to get information from the web in a more normalized fashion
Web Services
Web Services¶
“a software system designed to support interoperable machine-to-machine interaction over a network” - W3C
- provides a defined set of calls
- returns structured data
RSS is one of the earliest forms of Web Services
A single web-based endpoint provides a dynamically updated listing of content
Implemented in pure HTTP. Returns XML
Atom is a competing, but similar standard
There’s a solid Python library for consuming RSS: feedparser.
XML-RPC extended the essentially static nature of RSS by allowing users to call procedures and pass arguments.
- Calls are made via HTTP GET, by passing an XML document
- Returns from a call are sent to the client in XML
In python, you can access XML-RPC services using xmlrpc from the
standard library. It has two libraries, xmlrpc.client and
xmlrpc.server
SOAP extends XML-RPC in a couple of useful ways:
- It uses Web Services Description Language (WSDL) to provide meta-data about an entire service in a machine-readable format (Automatic introspection)
- It establishes a method for extending available data types using XML namespaces
There is no standard library module that supports SOAP directly.
- The best-known and best-supported module available is Suds
- The homepage is https://fedorahosted.org/suds/
- It can be installed using
easy_installorpip install - A fork of the library compatible with Python 3 does exist
I HATE SOAP
SOAP was invented in part to provide completely machine-readable interoperability.
Does that really work in real life?
Hardly ever
Another reason was to provide extensibility via custom types
Does that really work in real life?
Hardly ever
In addition, XML is a pretty inefficient medium for transmitting data. There’s a lot of extra characters transmitted that lack any meaning.
<?xml version="1.0"?>
<soap:Envelope xmlns:soap="http://www.w3.org/2003/05/soap-envelope">
<soap:Header>
</soap:Header>
<soap:Body>
<m:GetStockPrice xmlns:m="http://www.example.org/stock/Surya">
<m:StockName>IBM</m:StockName>
</m:GetStockPrice>
</soap:Body>
</soap:Envelope>
So, if neither of the original goals is really achieved by using SOAP
And if the transmission medium is too bloated to use
why pay all the overhead required to use the protocol?
Is there another way we could consider approaching the problem?
Enter REST
REST¶
Representational State Transfer
- Originally described by Roy T. Fielding (worth reading)
- Use HTTP for what it can do
- Read more in RESTful Web Services*
* Seriously. Buy it and read it
The XML-RCP/SOAP way:
- POST /getComment HTTP/1.1
- POST /getComments HTTP/1.1
- POST /addComment HTTP/1.1
- POST /editComment HTTP/1.1
- POST /deleteComment HTTP/1.1
The RESTful way:
- GET /comment/<id> HTTP/1.1
- GET /comment HTTP/1.1
- POST /comment HTTP/1.1
- PUT /comment/<id> HTTP/1.1
- DELETE /comment/<id> HTTP/1.1
REST is a Resource Oriented Architecture
The URL represents the resource we are working with
The HTTP Method indicates the action to be taken
The HTTP Code returned tells us the result (whether success or failure)
POST /comment HTTP/1.1 (creating a new comment):
- Success:
HTTP/1.1 201 Created - Failure (unauthorized):
HTTP/1.1 401 Unauthorized - Failure (NotImplemented):
HTTP/1.1 405 Not Allowed - Failure (ValueError):
HTTP/1.1 406 Not Acceptable
PUT /comment/<id> HTTP/1.1 (edit comment):
- Success:
HTTP/1.1 200 OK - Failure:
HTTP/1.1 409 Conflict
DELETE /comment/<id> HTTP/1.1 (delete comment):
- Success:
HTTP/1.1 204 No Content
REST uses JSON¶
JavaScript Object Notation:
- a lightweight data-interchange format
- easy for humans to read and write
- easy for machines to parse and generate
Based on Two Structures:
- object:
{ string: value, ...} - array:
[value, value, ]
pythonic, no?
JSON provides a few basic data types (see http://json.org/):
- string: unicode, anything but ”, \ and control characters
- number: any number, but json does not use octal or hexadecimal
- object, array (we’ve seen these above)
- true
- false
- null
No date type? OMGWTF??!!1!1
You have two options:
Option 1 - Unix Epoch Time (number):
>>> import time
>>> time.time()
1358212616.7691269
Option 2 - ISO 8661 (string):
>>> import datetime
>>> datetime.datetime.now().isoformat()
'2013-01-14T17:18:10.727240'
JSON in Python¶
You can encode python to json, and decode json back to python:
In [1]: import json
In [2]: array = [1, 2, 3]
In [3]: json.dumps(array)
Out[3]: '[1, 2, 3]'
In [4]: orig = {'foo': [1,2,3], 'bar': 'my resumé', 'baz': True}
In [5]: encoded = json.dumps(orig)
In [6]: encoded
Out[6]: '{"foo": [1, 2, 3], "bar": "my resum\\u00e9", "baz": true}'
In [7]: decoded = json.loads(encoded)
In [8]: decoded == orig
Out[8]: True
Customizing the encoder or decoder class allows for specialized serializations
the json module also supports reading and writing to file-like objects via
json.dump(fp) and json.load(fp) (note the missing ‘s’)
Remember duck-typing. Anything with a .write and a .read method is
file-like
This usage can be much more memory-friendly with large files/sources
Playing With REST¶
Let’s take a moment to play with REST.
We’ll use a common, public API provided by Google.
Geocoding
https://developers.google.com/maps/documentation/geocoding
Open a python interpreter using our virtualenv:
(soupenv)$ python
In [1]: import requests
In [2]: import json
In [3]: from pprint import pprint
In [4]: url = 'http://maps.googleapis.com/maps/api/geocode/json'
In [5]: addr = '1325 4th Ave, Seattle, 98101'
In [6]: parameters = {'address': addr, 'sensor': 'false'}
In [7]: resp = requests.get(url, params=parameters)
In [8]: data = resp.json()
You can do the same thing in reverse, supply latitude and longitude and get back address information:
In [15]: if data['status'] == 'OK':
....: pprint(data['results'])
....:
[{'address_components': [{'long_name': '1325',
'short_name': '1325',
...
'types': ['street_address']}]
Notice that there may be a number of results returned, ordered from most specific to least.
Mashing It Up¶
Google’s geocoding data is quite nice.
But it’s not in a format we can use directly to create a map
For that we need geojson
Moreover, formatting the data for all those requests is going to get tedious.
Luckily, people create wrappers for popular REST apis like google’s geocoding service.
Once such wrapper is geocoder, which provides not only google’s service, but many others under a single umbrella.
Install geocoder into your soupenv so that it’s available to use:
(soupenv)$ pip install geocoder
Our final step for tonight will be to geocode the results we have scraped from the inspection site.
We’ll then convert that to geojson, insert our own properties and map
the results.
Let’s begin by converting our script so that what we have so far is contained in a generator function
We’ll eventually sort our results and generate the top 10 or so for geocoding.
Open up mashup.py and copy everthing in the main block.
Add a new function result_generator to the mashup.py script. Paste the
code you copied from the main block and then update it a bit:
def result_generator(count):
use_params = {
'Inspection_Start': '2/1/2013',
'Inspection_End': '2/1/2015',
'Zip_Code': '98101'
}
# html, encoding = get_inspection_page(**use_params)
html, encoding = load_inspection_page('inspection_page.html')
parsed = parse_source(html, encoding)
content_col = parsed.find("td", id="contentcol")
data_list = restaurant_data_generator(content_col)
for data_div in data_list[:count]:
metadata = extract_restaurant_metadata(data_div)
inspection_data = get_score_data(data_div)
metadata.update(inspection_data)
yield metadata
Update the main block of your mashup.py script to use the new function:
if __name__ == '__main__':
for result in result_generator(10):
print result
Then run your script and verify that the only thing that has changed is the number of results that print.
(soupenv)$ python mashup.py
# you should see 10 dictionaries print here.
Add Geocoding¶
The API for geocoding with geocoder is the same for all providers.
You give an address, it returns geocoded data.
You provide latitude and longitude, it provides address data
In [1]: response = geocoder.google(<address>)
In [2]: response.json
Out[2]: # json result data
In [3]: response.geojson
Out[3]: # geojson result data
Let’s add a new function get_geojson to mashup.py
It will
- Take a result from our search as it’s input
- Get geocoding data from google using the address of the restaurant
- Return the geojson representation of that data
Try to write this function on your own
def get_geojson(result):
address = " ".join(result.get('Address', ''))
if not address:
return None
geocoded = geocoder.google(address)
return geocoded.geojson
Next, update our main block to get the geojson for each result and print
it:
if __name__ == '__main__':
for result in result_generator(10):
geojson = get_geojson(result)
print geojson
Then test your results by running your script:
(soupenv)$ python mashup.py
{'geometry': {'type': 'Point', 'coordinates': [-122.3393005, 47.6134378]},
'type': 'Feature', 'properties': {'neighborhood': 'Belltown',
'encoding': 'utf-8', 'county': 'King County', 'city_long': 'Seattle',
'lng': -122.3393005, 'quality': u'street_address', 'city': 'Seattle',
'confidence': 9, 'state': 'WA', 'location': u'1933 5TH AVE SEATTLE, WA 98101',
'provider': 'google', 'housenumber': '1933', 'accuracy': 'ROOFTOP',
'status': 'OK', 'state_long': 'Washington',
'address': '1933 5th Avenue, Seattle, WA 98101, USA', 'lat': 47.6134378,
'postal': '98101', 'ok': True, 'road_long': '5th Avenue', 'country': 'US',
'country_long': 'United States', 'street': '5th Ave'},
'bbox': [-122.3406494802915, 47.6120888197085, -122.3379515197085, 47.6147867802915]}
The properties of our geojson records are filled with data we don’t really
care about.
Let’s replace that information with some of the metadata from our inspection results.
We’ll update our get_geojson function so that it:
- Builds a dictionary containing only the values we want from our inspection record.
- Converts list values to strings (geojson requires this)
- Replaces the ‘properties’ of our geojson with this new data
- Returns the modified geojson record
See if you can make the updates on your own.
def get_geojson(result):
# ...
geocoded = geocoder.google(address)
geojson = geocoded.geojson
inspection_data = {}
use_keys = (
'Business Name', 'Average Score', 'Total Inspections', 'High Score'
)
for key, val in result.items():
if key not in use_keys:
continue
if isinstance(val, list):
val = " ".join(val)
inspection_data[key] = val
geojson['properties'] = inspection_data
return geojson
We are now generating a series of geojson Feature objects.
To map these objects, we’ll need to create a file which contains a
geojson FeatureCollection.
The structure of such a collection looks like this:
{'type': 'FeatureCollection', 'features': [...]}
Let’s update our main function to append each feature to such a
structure.
Then we can dump the structure as json to a file.
In mashup.py update the main block like so:
# add an import at the top:
import json
if __name__ == '__main__':
total_result = {'type': 'FeatureCollection', 'features': []}
for result in result_generator(10):
geojson = get_geojson(result)
total_result['features'].append(geojson)
with open('my_map.json', 'w') as fh:
json.dump(total_result, fh)
When you run the script nothing will print, but the new file will appear.
(soupenv)$ python mashup.py
This script is available as resources/session04/mashup_5.py
Display the Results¶
Once the new file is written you are ready to display your results.
Open your web browser and go to http://geojson.io
Then drag and drop the new file you wrote onto the map you see there.
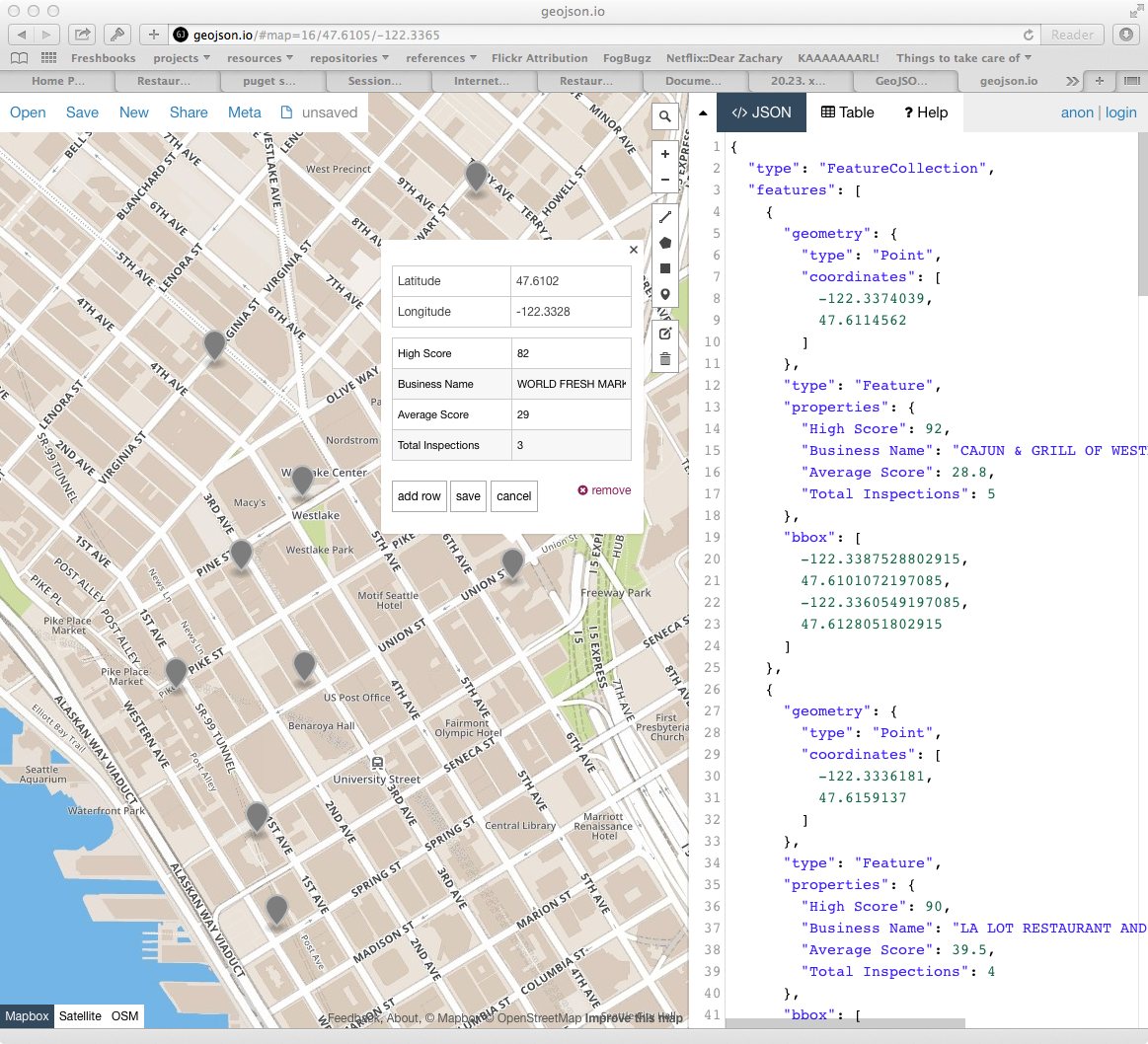
Wrap Up¶
We’ve built a simple mashup combining data from different sources.
We scraped health inspection data from the King County government site.
We geocoded that data.
And we’ve displayed the results on a map.
What other sources of data might we choose to combine?
Check out programmable web to see some of the possibilities
Homework¶
For your homework this week, you’ll be polishing this mashup.
Begin by sorting the results of our search by the average score (can you do this and still use a generator for getting the geojson?).
Then, update your script to allow the user to choose how to sort, by average, high score or most inspections:
(soupenv)$ python mashup.py highscore
Next, allow the user to choose how many results to map:
(soupenv)$ python mashup.py highscore 25
Or allow them to reverse the results, showing the lowest scores first:
(soupenv)$ python mashup.py highscore 25 reverse
If you’re feeling particularly adventurous, see if you can use the argparse module from the standard library to handle command line arguments
More Fun¶
Next, try adding a bit of information to your map by setting the
marker-color property. This will display a marker with the provided
css-style color (#FF0000)
See if you can make the color change according to the values used for the sorting of the list. Either vary the intensity of the color, or the hue.
Finally, if you are feeling particularly frisky, you can update your script to automatically open a browser window with your map loaded on geojson.io.
To do this, you’ll want to read about the webbrowser module from the standard library.
In addition, you’ll want to read up on using the URL parameters API for geojson.io. Click on the help tab in the sidebar to view the information.
You will also need to learn about how to properly quote special characters
for a URL, using the urllib.parse quote function.
Submitting Your Work¶
Create a github repository to contain your mashup work. Start by populating it with the script as we finished it today (mashup_5.py).
As you implement the above features, commit early and commit often.
When you’re ready for us to look it over, email a link to your repository to Maria and I.