Session 03¶

The Wandering Angel http://www.flickr.com/photos/wandering_angel/1467802750/ - CC-BY
CGI, WSGI and Living Online¶
Wherein we discover the gateways to dynamic processes on a server.
But First¶
Homework Review and Questions
Previously¶
- You’ve learned about passing messages back and forth with sockets
- You’ve created a simple HTTP server using sockets
- You may even have made your server dynamic by returning the output of a python script.
What if you want to pass information to that script?
How can you give the script access to information about the HTTP request itself?
Stepping Away: The Environment¶
A computer has an environment:
in *nix, you can see this in a shell:
$ printenv
TERM_PROGRAM=iTerm.app
...
or in Windows at the command prompt:
C:\> set
ALLUSERSPROFILE=C:\ProgramData
...
or in PowerShell:
PS C:\> Get-ChildItem Env:
ALLUSERSPROFILE C:\ProgramData
...
In a bash shell we can do this:
$ export VARIABLE='some value'
$ echo $VARIABLE
some value
or at a Windows command prompt:
C:\Users\Administrator\> set VARIABLE='some value'
C:\Users\Administrator\> echo %VARIABLE%
'some value'
or in PowerShell:
PS C:\> $env:VARIABLE = "some value"
PS C:\> Get-ChildItem Env:VARIABLE
'some value'
These new values are now part of the environment
*nix:
$ printenv
...
VARIABLE=some value
Windows:
C:\> set
...
VARIABLE='some value'
PowerShell:
PS C:\> Get-ChildItem Env:
...
VARIABLE 'some value'
We can see this environment in Python, too:
$ python
>>> import os
>>> print(os.environ['VARIABLE'])
some_value
>>> print(os.environ.keys())
['VERSIONER_PYTHON_PREFER_32_BIT', 'VARIABLE',
'LOGNAME', 'USER', 'PATH', ...]
You can alter os environment values while in Python:
>>> os.environ['VARIABLE'] = 'new_value'
>>> print(os.environ['VARIABLE'])
new_value
But that doesn’t change the original value, outside Python:
>>> ^D
$ echo this is the value: $VARIABLE
this is the value: some_value
<OR>
C:\> \Users\Administrator\> echo %VARIABLE%
'some value'
- Subprocesses inherit their environment from their Parent
- Parents do not see changes to environment in subprocesses
- In Python, you can actually set the environment for a subprocess explicitly
subprocess.Popen(args, bufsize=0, executable=None,
stdin=None, stdout=None, stderr=None,
preexec_fn=None, close_fds=False,
shell=False, cwd=None, env=None, # <-------
universal_newlines=False, startupinfo=None,
creationflags=0)
CGI - The Web Environment¶
CGI is little more than a set of standard environmental variables
What is CGI¶
First discussed in 1993, formalized in 1997, the current version (1.1) has been in place since 2004.
From the preamble:
This memo provides information for the Internet community. It does not
specify an Internet standard of any kind.
-- RFC 3875 - CGI Version 1.1: http://tools.ietf.org/html/rfc3875
4. The CGI Request . . . . . . . . . . . . . . . . . . . . . . . 10
4.1. Request Meta-Variables . . . . . . . . . . . . . . . . . 10
4.1.1. AUTH_TYPE. . . . . . . . . . . . . . . . . . . . 11
4.1.2. CONTENT_LENGTH . . . . . . . . . . . . . . . . . 12
4.1.3. CONTENT_TYPE . . . . . . . . . . . . . . . . . . 12
4.1.4. GATEWAY_INTERFACE. . . . . . . . . . . . . . . . 13
4.1.5. PATH_INFO. . . . . . . . . . . . . . . . . . . . 13
4.1.6. PATH_TRANSLATED. . . . . . . . . . . . . . . . . 14
4.1.7. QUERY_STRING . . . . . . . . . . . . . . . . . . 15
4.1.8. REMOTE_ADDR. . . . . . . . . . . . . . . . . . . 15
4.1.9. REMOTE_HOST. . . . . . . . . . . . . . . . . . . 16
4.1.10. REMOTE_IDENT . . . . . . . . . . . . . . . . . . 16
4.1.11. REMOTE_USER. . . . . . . . . . . . . . . . . . . 16
4.1.12. REQUEST_METHOD . . . . . . . . . . . . . . . . . 17
4.1.13. SCRIPT_NAME. . . . . . . . . . . . . . . . . . . 17
4.1.14. SERVER_NAME. . . . . . . . . . . . . . . . . . . 17
4.1.15. SERVER_PORT. . . . . . . . . . . . . . . . . . . 18
4.1.16. SERVER_PROTOCOL. . . . . . . . . . . . . . . . . 18
4.1.17. SERVER_SOFTWARE. . . . . . . . . . . . . . . . . 19
Running CGI¶
You have a couple of options:
- Python Standard Library CGIHTTPServer
- Apache
- IIS (on Windows)
- Some other HTTP server that implements CGI (lighttpd, ...?)
Let’s keep it simple by using the Python module
In the class resources for this session, you’ll find a directory named cgi.
Make a copy of that folder in your class working directory.
Windows Users, you may have to edit the first line of
cgi/cgi-bin/cgi_1.py to point to your python executable.
- Open two terminal windows in this
cgidirectory - In the first terminal, run
python -m http.server --cgi - Open a web browser and load
http://localhost:8000/ - Click on CGI Test 1
- Your browser might show a 404 or 403 error
- If you see something like that, check the permissions for
cgi-binandcgi_1.py - The file must be executable, the
cgi-bindirectory needs to be readable and executable.
Remember that you can use the bash chmod command to change permissions
in *nix: chmod a+x cgi-bin/cgi_1.py
Windows users, use the ‘properties’ context menu to get to permissions, just grant ‘full’
Problems with permissions can lead to failure. So can scripting errors
- Open
cgi/cgi-bin/cgi_1.pyin an editor - Before where it says
cgi.test(), add a single line:
1 / 0
Reload your browser, what happens now?
CGI is famously difficult to debug. There are reasons for this:
- CGI is designed to provide access to runnable processes to the internet
- The internet is a wretched hive of scum and villainy
- Revealing error conditions can expose data that could be exploited
Back in your editor, add the following lines, just below import cgi:
import cgitb
cgitb.enable()
Now, reload again.
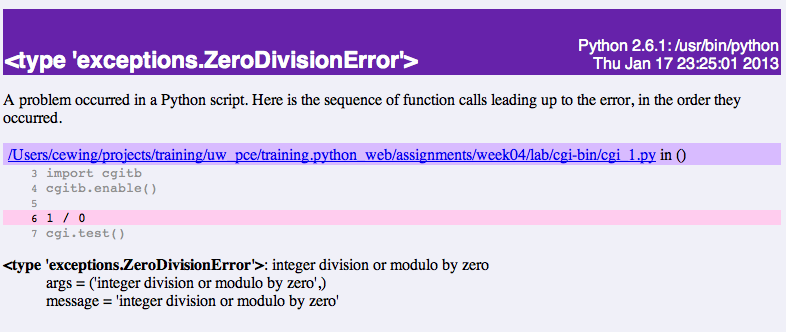
Let’s fix the error from our traceback. Edit your cgi_1.py file to match:
#!/usr/bin/env python
import cgi
import cgitb
cgitb.enable()
cgi.test()
Notice the first line of that script: #!/usr/bin/env python.
This is called a shebang (short for hash-bang)
It tells the system what executable program to use when running the script.
CGI Process Execution¶
Servers like http.server --cgi run CGI scripts as a system user called
nobody.
This is just like you calling:
$ ./cgi_bin/cgi_1.py
In fact try that now in your second terminal (use the real path), what do you get?
Windows folks, you may need C:\>python cgi-bin/cgi_1.py
Notice what is missing?
There are a couple of important facts about CGI that derive from this:
- The script must include a shebang so that the system knows how to run it.
- The script must be executable.
- The executable named in the shebang will be called as the nobody user.
- This is a security feature to prevent CGI scripts from running as a user with any privileges.
- This means that the executable from the script shebang must be one that anyone can run.
CGI is largely a set of agreed-upon environmental variables.
We’ve seen how environmental variables are found in python in
os.environ
We’ve also seen that at least some of the variables in CGI are not part of the system environment.
Where do they come from?
Let’s find ‘em. In a terminal fire up python:
In [1]: from http import server
In [2]: server.__file__
Out[2]: '/Users/cewing/pythons/parts/opt/lib/python3.5/http/server.py'
In [3]: !subl '/Users/cewing/pythons/parts/opt/lib/python3.5/http/server.py'
If you don’t have the subl command, or another one that starts your
editor, copy this path and open it in your text editor.
From http/server.py, in the CGIHTTPRequestHandler class, in the
run_cgi method:
env = copy.deepcopy(os.environ)
env['SERVER_SOFTWARE'] = self.version_string()
env['SERVER_NAME'] = self.server.server_name
env['GATEWAY_INTERFACE'] = 'CGI/1.1'
...
if self.have_fork:
# Unix -- fork as we should
...
pid = os.fork()
...
try:
...
os.execve(scriptfile, args, env)
...
else:
# Non-Unix -- use subprocess
import subprocess
...
p = subprocess.Popen(cmdline,
...
env = env
)
...
And that’s it, the big secret. The server takes care of setting up the environment so it has what is needed.
Now, in reverse. How does the information that a script creates end up in your browser?
A CGI Script must print its results to stdout.
Use the same method as above to import and open the source file for the
cgi module. Note what test does for an example of this.
def test(environ=os.environ):
...
print("Content-type: text/html")
print()
try:
form = FieldStorage() # Replace with other classes to test those
print_directory()
print_arguments()
print_form(form)
...
except:
print_exception()
What the Server Does:
- parses the request
- sets up the environment, including HTTP and SERVER variables
- sends a
HTTP/1.1 200 OK\r\nfirst line to the client - figures out if the URI points to a CGI script and runs it
- appends what comes from the script on stdout and sends that back
What the Script Does:
- names appropriate executable in the shebang line
- uses os.environ to read information from the HTTP request
- builds any and all extra HTTP Headers
(Content-type:, Content-length:, ...) - prints the headers, empty line and script output (body) to stdout
In-Class Exercise I¶
You’ve seen the output from the cgi.test() method from the cgi module.
Let’s make our own version of this.
- In the directory
cgi-binyou will find the filecgi_2.py. - Open that file in your editor.
- The script contains some html with text containing placeholders.
- You should use Python and the CGI environment to fill the the blanks.
- You can view the results of your work by loading
http://localhost:8000/and clicking on Exercise One
GO
Getting Data from Users¶
All this is well and good, but where’s the dynamic stuff?
It’d be nice if a user could pass form data to our script for it to use.
In HTTP, data is often passed to the server as a part of a URL called the query string
The URL query string is formatted as name=value pairs, separated by the
ampersand (&) character
The entire query string is separated from other parts of the URL by a question mark:
http://localhost:8000/cgi_bin/somescript.py?a=23&b=46&b=92
In the cgi module, we get access to the query string with the
FieldStorage class:
import cgi
form = cgi.FieldStorage()
stringval = form.getvalue('a', None)
listval = form.getlist('b')
- The values in the
FieldStorageare always strings getvalueallows you to return a default, in case the field isn’t presentgetlistalways returns a list: empty, one-valued, or as many values as are present
In-Class Exercise II¶
Let’s create a dynamic adding machine.
- In the
cgi-bindirectory you’ll findcgi_sums.py. - In the
index.htmlfile in thecgidirectory, the third link leads to this file. - You will use the structure of that link, and what you learned just now about
cgi.FieldStorage. - Complete the cgi script in
cgi_sums.pyso that the result of adding all operands sent via the url query is returned. - Return the results as plain text, with the appropriate
Content-Typeheader.
form = cgi.FieldStorage()
operands = form.getlist('operand')
msg = "your total is {total}"
try:
total = sum(map(int, operands))
msg = msg.format(total=total)
except (ValueError, TypeError):
msg = "Unable to calculate a sum, please provide integer operands"
print("Content-Type: text/plain")
print("Content-Length: %s" % len(msg))
print()
print(msg)
Let’s take a break here, before continuing
WSGI¶
The Web Server Gateway Interface
CGI Problems¶
CGI is great, but there are problems:
- Code is executed in a new process
- Every call to a CGI script starts a new process on the server
- Starting a new process is expensive in terms of server resources
- Especially for interpreted languages like Python
How do we overcome this problem?
The most popular approach is to have a long-running process inside the server that handles CGI scripts.
FastCGI and SCGI are existing implementations of CGI in this fashion.
The PHP scripting language works in much the same way.
The Apache module mod_python offers a similar capability for Python code.
- Each of these options has a specific API
- None are compatible with each-other
- Code written for one is not portable to another
This makes it much more difficult to share resources
A Solution¶
Enter WSGI, the Web Server Gateway Interface.
Other alternatives are specific implementations of the CGI standard.
WSGI is itself a new standard, not an implementation.
WSGI is generalized to describe a set of interactions.
Developers can write WSGI-capable apps and deploy them on any WSGI server.
Read the original WSGI spec: http://www.python.org/dev/peps/pep-0333
There is also an update for Python 3:
https://www.python.org/dev/peps/pep-3333
Apps and Servers¶
WSGI consists of two parts, a server and an application.
A WSGI Server must:
- set up an environment, much like the one in CGI
- provide a method
start_response(status, headers, exc_info=None) - build a response body by calling an application, passing
environmentandstart_responseas args - return a response with the status, headers and body
A WSGI Appliction must:
- Be a callable (function, method, class)
- Take an environment and a
start_responsecallable as arguments - Call the
start_responsemethod. - Return an iterable of 0 or more strings, which are treated as the body of the response.
from some_application import simple_app
def build_env(request):
# put together some environment info from the reqeuest
return env
def handle_request(request, app):
environ = build_env(request)
iterable = app(environ, start_response)
for data in iterable:
# send data to client here
def start_response(status, headers):
# start an HTTP response, sending status and headers
# listen for HTTP requests and pass on to handle_request()
serve(simple_app)
Where the simplified server above is not functional, this is a complete app:
def application(environ, start_response)
status = "200 OK"
body = "Hello World\n"
response_headers = [('Content-type', 'text/plain'),
('Content-length', len(body))]
start_response(status, response_headers)
return [body]
A third part of the puzzle is something called WSGI middleware
- Middleware implements both the server and application interfaces
- Middleware acts as a server when viewed from an application
- Middleware acts as an application when viewed from a server
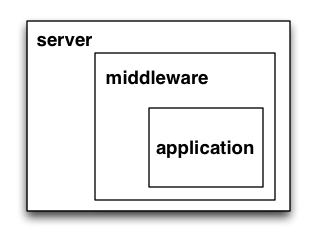
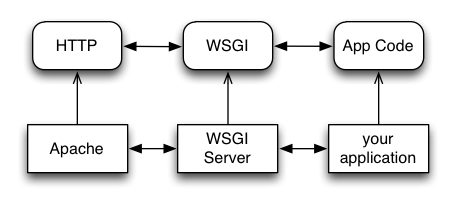
WSGI Servers:
HTTP <—> WSGI
WSGI Applications:
WSGI <—> app code
The WSGI Stack can thus be expressed like so:
HTTP <—> WSGI <—> app code
The Python standard lib provides a reference implementation of WSGI:
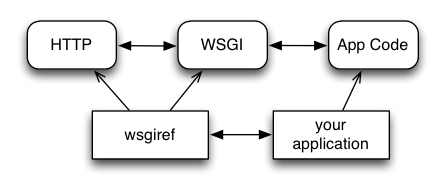
You can also deploy with Apache as your HTTP server, using mod_wsgi:
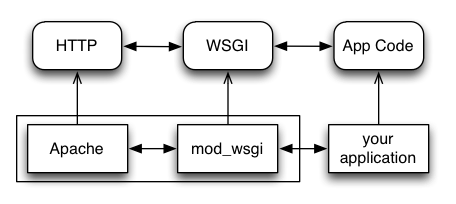
Finally, it is also common to see WSGI apps deployed via a proxied WSGI server:
The WSGI Environment¶
- REQUEST_METHOD:
- The HTTP request method, such as “GET” or “POST”. This cannot ever be an empty string, and so is always required.
- SCRIPT_NAME:
- The initial portion of the request URL’s “path” that corresponds to the application object, so that the application knows its virtual “location”. This may be an empty string, if the application corresponds to the “root” of the server.
- PATH_INFO:
- The remainder of the request URL’s “path”, designating the virtual “location” of the request’s target within the application. This may be an empty string, if the request URL targets the application root and does not have a trailing slash.
- QUERY_STRING:
- The portion of the request URL that follows the ”?”, if any. May be empty or absent.
- CONTENT_TYPE:
- The contents of any Content-Type fields in the HTTP request. May be empty or absent.
- CONTENT_LENGTH:
- The contents of any Content-Length fields in the HTTP request. May be empty or absent.
- SERVER_NAME, SERVER_PORT:
- When combined with SCRIPT_NAME and PATH_INFO, these variables can be used to complete the URL. Note, however, that HTTP_HOST, if present, should be used in preference to SERVER_NAME for reconstructing the request URL. See the URL Reconstruction section below for more detail. SERVER_NAME and SERVER_PORT can never be empty strings, and so are always required.
- SERVER_PROTOCOL:
- The version of the protocol the client used to send the request. Typically this will be something like “HTTP/1.0” or “HTTP/1.1” and may be used by the application to determine how to treat any HTTP request headers. (This variable should probably be called REQUEST_PROTOCOL, since it denotes the protocol used in the request, and is not necessarily the protocol that will be used in the server’s response. However, for compatibility with CGI we have to keep the existing name.)
- HTTP_ Variables:
- Variables corresponding to the client-supplied HTTP request headers (i.e., variables whose names begin with “HTTP_”). The presence or absence of these variables should correspond with the presence or absence of the appropriate HTTP header in the request.
Seem Familiar?
In-Class Exercise III¶
Let’s start simply. We’ll begin by repeating our first CGI exercise in WSGI
- Find the
wsgidirectory in the class resources. Copy it to your working directory. - Open the file
wsgi_1.pyin your text editor. - We will fill in the missing values using Python and the wsgi
environ, just as we useos.environin cgi
But First
if __name__ == '__main__':
from wsgiref.simple_server import make_server
srv = make_server('localhost', 8080, application)
srv.serve_forever()
Note that we pass our application function to the server factory
We don’t have to write a server, wsgiref does that for us.
In fact, you should never have to write a WSGI server.
def application(environ, start_response):
response_body = body % (
environ.get('SERVER_NAME', 'Unset'), # server name
...
)
status = '200 OK'
response_headers = [('Content-Type', 'text/html'),
('Content-Length', str(len(response_body)))]
start_response(status, response_headers)
return [response_body.encode('utf8')]
We do not define start_response, the application does that.
We are responsible for determining the HTTP status.
And the content we hand back must be bytes, not unicode.
You can run this script with python:
$ python wsgi_1.py
This will start a wsgi server. What host and port will it use?
Point your browser at http://localhost:8080/. Did it work?
Go ahead and fill in the missing bits. Use the environ passed into
application
WSGI is a long-running process.
The file you are editing is not reloaded after you edit it.
You’ll need to quit and re-run the script between edits.
Notice the use of pprint.pprint, check your terminal for useful output.
A WSGI Application¶
So now we’ve learned a bit about the WSGI specification and how a WSGI application can get data that comes in via an HTTP request.
Let’s create a multi-page wsgi application.
It will serve a small database of python books.
The database (with a very simple api) can be found in wsgi/bookdb.py
- We’ll need a listing page that shows the titles of all the books
- Each title will link to a details page for that book
- The details page for each book will display all the information and have a link back to the list
When viewing our first wsgi app, do we see the name of the wsgi application script anywhere in the URL?
In our wsgi application script, how many applications did we actually have?
How are we going to serve different types of information out of a single application?
We have to write an app that will map our incoming request path to some code that can handle that request.
This process is called dispatch. There are many possible approaches.
Let’s begin by designing this piece of our app.
Open bookapp.py from the wsgi folder. We’ll do our work here.
The wsgi environment gives us access to PATH_INFO.
This value is the URI from the client’s HTTP request.
We can design the URLs that our app will use to assist us in routing.
Let’s declare that any request for / will map to the list page.
We can also say that the URL for a book will look like this:
http://localhost:8080/book/<identifier>
Writing resolve_path¶
Let’s write a function, called resolve_path in our application file.
- It should take the PATH_INFO value from environ as an argument.
- It should return the function that will be called.
- It should also return any arguments needed to call that function.
- This implies of course that the arguments should be part of the PATH
def resolve_path(path):
urls = [(r'^$', books),
(r'^book/(id[\d]+)$', book)]
matchpath = path.lstrip('/')
for regexp, func in urls:
match = re.match(regexp, matchpath)
if match is None:
continue
args = match.groups([])
return func, args
# we get here if no url matches
raise NameError
We need to hook our new dispatch function into the application.
- The path should be extracted from
environ. - The dispatch function should be used to get a function and arguments
- The body to return should come from calling that function with those arguments
- If an error is raised by calling the function, an appropriate response should be returned
- If the router raises a NameError, the application should return a 404 response
def application(environ, start_response):
headers = [("Content-type", "text/html")]
try:
path = environ.get('PATH_INFO', None)
if path is None:
raise NameError
func, args = resolve_path(path)
body = func(*args)
status = "200 OK"
except NameError:
status = "404 Not Found"
body = "<h1>Not Found</h1>"
except Exception:
status = "500 Internal Server Error"
body = "<h1>Internal Server Error</h1>"
finally:
headers.append(('Content-length', str(len(body))))
start_response(status, headers)
return [body.encode('utf8')]
Test Your Work¶
Once you’ve got your script settled, run it:
$ python bookapp.py
Then point your browser at http://localhost:8080/
http://localhost/book/id3http://localhost/book/id73/http://localhost/sponge/damp
Did that all work as you would have expected?
Building the Book List¶
The function books should return an html list of book titles where each
title is a link to the detail page for that book
- You’ll need all the ids and titles from the book database.
- You’ll need to build a list in HTML using this information
- Each list item should have the book title as a link
- The href for the link should be of the form
/book/<id>
def books():
all_books = DB.titles()
body = ['<h1>My Bookshelf</h1>', '<ul>']
item_template = '<li><a href="/book/{id}">{title}</a></li>'
for book in all_books:
body.append(item_template.format(**book))
body.append('</ul>')
return '\n'.join(body)
Test Your Work¶
Quit and then restart your application script:
$ python bookapp.py
Then reload the root of your application:
http://localhost:8080/
You should see a nice list of the books in the database. Do you?
Click on a link to view the detail page. Does it load without error?
Showing Details¶
The next step of course is to polish up those detail pages.
- You’ll need to retrieve a single book from the database
- You’ll need to format the details about that book and return them as HTML
- You’ll need to guard against ids that do not map to books
In this last case, what’s the right HTTP response code to send?
def book(book_id):
page = """
<h1>{title}</h1>
<table>
<tr><th>Author</th><td>{author}</td></tr>
<tr><th>Publisher</th><td>{publisher}</td></tr>
<tr><th>ISBN</th><td>{isbn}</td></tr>
</table>
<a href="/">Back to the list</a>
"""
book = DB.title_info(book_id)
if book is None:
raise NameError
return page.format(**book)
Quit and restart your script one more time
Then poke around at your application and see the good you’ve made
And your application is portable and sharable
It should run equally well under any wsgi server
Next steps for an app like this might be:
- Create a shared full page template and incorporate it into your app
- Improve the error handling by emitting error codes other than 404 and 500
- Swap out the basic backend here with a different one, maybe a Web Service?
- Think about ways to make the application less tightly coupled to the pages it serves
Homework¶
For your homework this week, you’ll be creating a wsgi application of your own.
You’ll create an online calculator that can perform several operations
You’ll need to support:
- Addition
- Subtraction
- Multiplication
- Division
Your users should be able to send appropriate requests and get back proper responses:
http://localhost:8080/multiply/3/5 => 15
http://localhost:8080/add/23/42 => 65
http://localhost:8080/divide/6/0 => HTTP "400 Bad Request"
To submit your homework:
- Create a new github repository. Call it
wsgi-calc. - Add a python script to it called
calculator.py. - Your script should be runnable using
$ python calculator.py - When the script is running, I should be able to view your application in my browser.
- I should be able to see a home page that explains how to perform calculations.
Your repository should include a README.md file.
Include all instructions I need to successfully run and view your script.
When you are done, send Maria and I an email with a link to your repository.
One Last Task¶
Next week we will be installing Python packages that are not part of the standard library.
This is a common occurence in web development. But it can be hazardous.
In order to practice safe development I am going to ask you to read and follow through a brief tutorial I’ve created on the subject.
If you have any trouble, or if things do not work the way they are supposed to, please reach out. We will need this to be working next week.
Wrap-Up¶
For educational purposes, you might wish to take a look at the source code for
the wsgiref module. It’s the canonical example of a simple wsgi server
>>> import wsgiref
>>> wsgiref.__file__
'/full/path/to/your/copy/of/wsgiref.py'
...
See you Next Time